After this past weeks readings and class discussion on Digitization, our assignment was to do some work with OCR (Optical Character Recognition.) This was a three part assignment: 1. Use Google Drive’s OCR (Google Drive Classic has one, their new Drive does not), 2. Look at Chronicling America’s OCR and 3. Find an OCR in your field and assess it. This was a very interesting (and slightly deflating) practicum that left me with a lot of questions.
Google Drive OCR
Dr. Robertson supplied images that he took of some Pinkerton Detective Agency Documents. I first ran the assigned image through the OCR without any editing. After I saw the resulting text, I edited the image and ran it through the OCR again.

 The Unedited Image did not fair well. Originally I uploaded the image without even rotating it to portrait. The OCR did not pick up any text. After rotating the image, it recognized the text but gave me poor results. It was able to work through the entire document but missed a lot of the words. For example the title “Mrs.” was translated into “Hr.” a couple times. At one point, the OCR reader got it correct but then misspelled it later in the document. The output text also varied in font style, size and emphasis.
The Unedited Image did not fair well. Originally I uploaded the image without even rotating it to portrait. The OCR did not pick up any text. After rotating the image, it recognized the text but gave me poor results. It was able to work through the entire document but missed a lot of the words. For example the title “Mrs.” was translated into “Hr.” a couple times. At one point, the OCR reader got it correct but then misspelled it later in the document. The output text also varied in font style, size and emphasis.


After this somewhat depressing output I decreased the Saturation while increasing the Contrast of the image. This made the text “pop” on the page. It also made the image a grey scale image which in one of the readings it was said to help the OCR function better. I also used the Sharpness setting which helped make certain letters easier to read (e, o, r), though I don’t know what exactly it did. The results from the Edited Image were worse than tan before. Not only did it misspell words, it only gave me seven random lines of text.
I shared my results with Ron Martin who was assigned the same image as me. He used Picassa, a Microsoft image editing software. He wasn’t able to improve the OCR rate either. We both got pretty shoddy results from the Google Drive OCR.
Chronicling America
Salt Lake City Herald
February 20, 1891; Front Page


The OCR actually did a pretty good job. You can see that it has issues with similar looking letters. For example the word “special,” it translates it to “spccal.” The OCR did not see a different between the “e” and “c” and completely missed the “i.” I also noticed that it doesn’t bring any punctuation or symbols over. You can see this in the missing brackets at the beginning of the article as well as the quotation marks on the eighth line. While the OCR did a fine job, the newspaper is in great condition. There doesn’t appear to be any issues with folding or bleed through and the text still looks fairly crisp.
Gainesville Daily Sun
January 1, 1905; Third Page

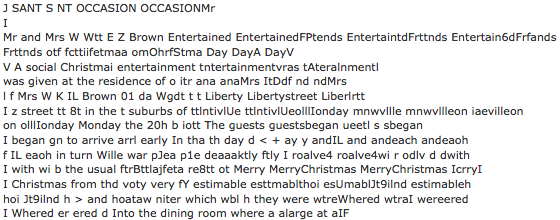
This copy of the Gainesville Daily Sun has seen better days. The pages are very faded and you can see build up of dirt or grime. The OCR struggled more with this page than the previous Salt Lake City Herald. At some points, words are repeated in the text translation. “The guests began to arrive…” has the word guest twice in the text output. I am not sure what the OCR is doing there. You can also see the Merry Christmas line is also repeated twice. I hadn’t noticed this issue with the other pages as much as with this page. I am interested to see why the OCR repeats the words in the text output. Compared to the Google Drive OCR, the text is all uniform in size and font. Also Chronicling America’s OCR follows the capitalization of the original document.
The Daily Chattanooga Rebel
June 9, 1864; Front Page


This last page from Chronicling America is older than the previous two. It is extremely faded, crooked and you can see various points of damage from what looks to be creases. I wasn’t expecting a good translation from the OCR but I wanted to see what it would pick up. It missed a lot of the text. I also find it interesting that the OCR inserted so much punctuation like dashes, quotations, semi-colons etc. In the previous pages, the OCR missed the punctuation.
Mormon History OCR
Nauvoo Expositor
June 7, 1844; Front page
I couldn’t find a website that provided its own OCR that also housed Mormon History documents (outside of Chronicling America.) Instead I went to signaturebookslibrary.org and perused their newspaper section. I found a PDF copy of a the Nauvoo Expositor. While the website I downloaded it from did have facsimiles, I ran the original document through Google Drive’s OCR.


The page has some harsh folds, smudge text and an overall faded look. The OCR did fairly well working through the text. You can see a recurring error roughly where the vertical fold goes through the text. The OCR also struggled with some letters that look similar (“a” and “o”) as well as catching the dashes for words that were completed on the following line. Overall, I am impressed with the fairly high accuracy from this page. I am interested in putting other pages through Google Drive and seeing the end result.