Text Formatting:
The editors of each collection provided additional information. Such things as a brief biographical sketch of each minister, numerous footnotes for historical context and scriptural citations, and page numbers and headers. Before I could start cleaning up the data, I needed to decide what to do with this additive information.
Biographical Information: I removed this information from each sermon. While it did provide a summary background to the minister, it wasn’t what I was interested in text mining and would only skew the information.
Historical Footnotes: I decided to remove all historical footnotes. My attempt was to text mine documents as close to the original sermons as possible. It was hard to delete some historical footnotes as they provided ample information for context.
Scriptural Footnote: I went back and forth about keeping these citations. While not actually a part of the sermon, it does provide me with a scriptural reference. In the end, I decided to keep these citations but standardize them. I changed the roman numeral chapters into arabic numbering, like the verses. I also wrote out the entire book if an abbreviation was used. Finally, I changed the in-text footnote marker to an asterisk. By using an asterisk for every citation, I could simply count up the number of asterisks in the corpus to find the number of scriptural citations provided by the editors. Also, asterisks don’t appear in the text at all, so there would be no inflation or dual use of the symbol.

Header and Page Numbers: At the top of each page was either the title of the collection or the title of the sermon (depending on if the page number was even or odd). These titles will greatly inflate the various word frequencies associated with their title. I decided that I had to remove every header and page number.
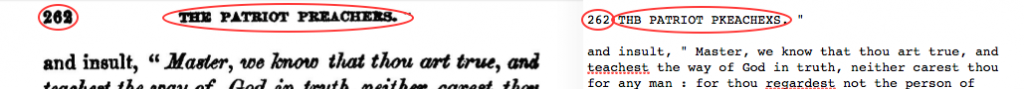
Cleaning OCR:
The Internet Archive provides a Full Text format (also described as machine readable text) of each collection. They accomplished this by feeding PDF copies of the collections through an Optical Character Recognition (OCR) program. OCR operates by comparing each character from the document against a stored dictionary of characters. The accuracy of OCR is greatly affected by the document’s resolution, contrast, physical quality etc.
Before I can feed these collections through my text mining program, I needed to clean the documents up. I did this by copying each sermon into a separate .txt or .rtf file. I then compared the .txt file against the PDF version of each sermon. The second collection, The Pulpit of the American Revolution, contained less errors than did the first. I would attribute this to better scans and a softer contrast between the text and the page. I have included example images below of issues with the OCRed text.
Common Textual Errors: An “h” would often become a “li” as well as a “u” would become an “n” or vice versa.

Stretched Text: During the scanning process, the bottom of the page wasn’t scanned properly thus making the text illegible to the OCR.
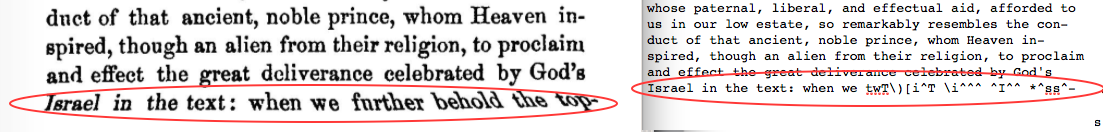
End of the line hyphenation: The text analysis program would not be able to recognize words that had been separated between lines by hyphenations. This was the most common “fix” I had to do.

Markings and Blemishes: The OCR, not knowing the difference, will read blemishes and markings into the text.

Bleed on the Page: While happening infrequently, bleeds on the page often leads the OCR to skip the line entirely.
