By way of introduction to using Text-mining, I was able to play around on four different tools. The first three (Google Book n-gram, Bookworm:Chronicling America, New York Times Chronicle) provide their own corpus of materials that will be mined while the fourth, Voyant, you create your own corpus. For the sake of my assignment, I searched the term “Mormon” through the first three text mining tools.
Google Book n-gram
Google Book n-gram searches through the corpus of books that Google has digitized. You can specify what corpus to use (American English, British English, French etc.) to get a more specified result. You can search up to a 5-gram (a 5 word phrase) in Google Book n-gram, which is nice for tracking the use of certain phrases or titles of companies etc. While I searched “The Church of Jesus Christ” and got nothing in return, I decided to search the more common term, “Mormon” through the database.
Bookworm: Chronicling America
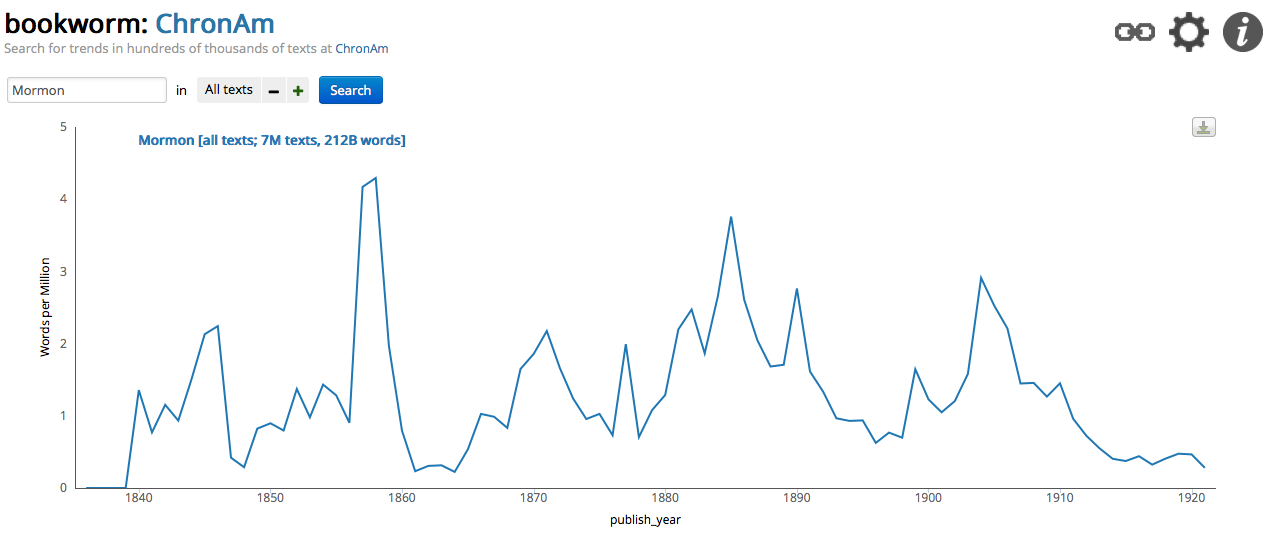
On the Bookworm site, you can choose which corpus of materials you would like to search. They have five different collections that you can search. I chose Chronicling America as it is a corpus of newspapers, including many local papers, from 41 states and the District of Columbia. At each point along the graph, you can click the value and see the newspaper articles.
NYT Chronicle
This is a relatively new site. The New York Times provides their entire corpus of work up to the present. At each point along the graph, you can click on a year and view the various articles.
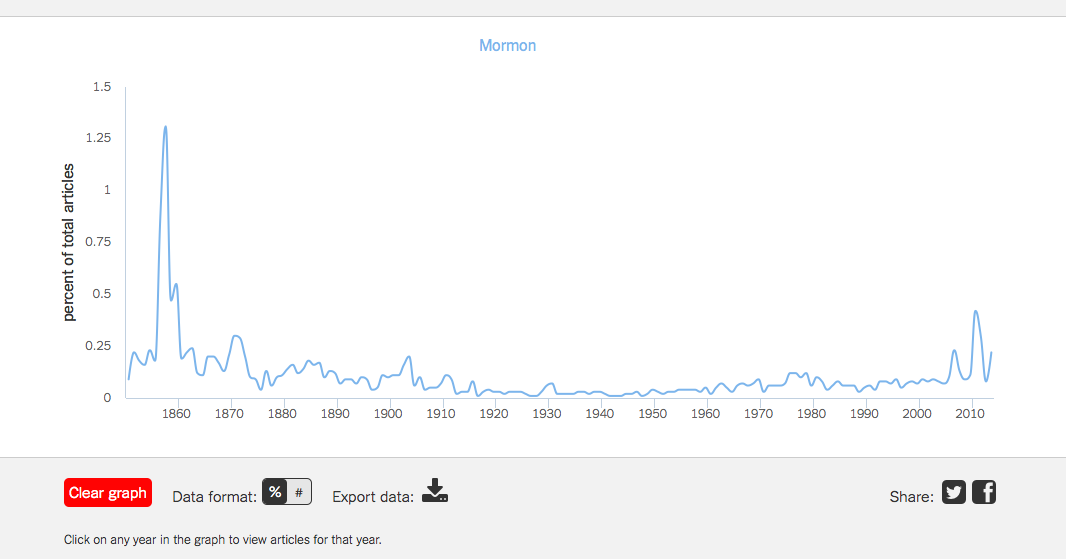
For both the NYT Chronicle and Bookworm: Chronicling America, you can see the term Mormon piques in 1858. It isn’t completely surprising since the Utah War occurred from 1857-1858. However, the largest spike in Google Books n-gram occurred in the 1880s. This was a tense time for Mormons as they were at odds with the Federal Government. I am not able to look through the various books listed in Google Book n-gram but Mormonism became a somewhat popular topic to write about. In 1887, Sir Arthur Conan Doyle wrote the Sherlock Holmes book A Study in Scarlet which *SPOILER* had the “evil” Mormons as the antagonists. The 1880s was also towards the end of the difficulty with the federal government. The following decade would see Utah admitted to the Union as a state on January 4th, 1896.
While Bookworm: Chronicling America does not cover the most recent years, NYT Chronicle does and it shows a spike in 2011 in the use of the term Mormon. This can easily be attributed to the Presidential run of Mitt Romney. However, a note on the units of the graph. Currently the y-axis on the NYT Chronicle is percent of articles. When I switched the y-axis to total number of articles, it looks like this:
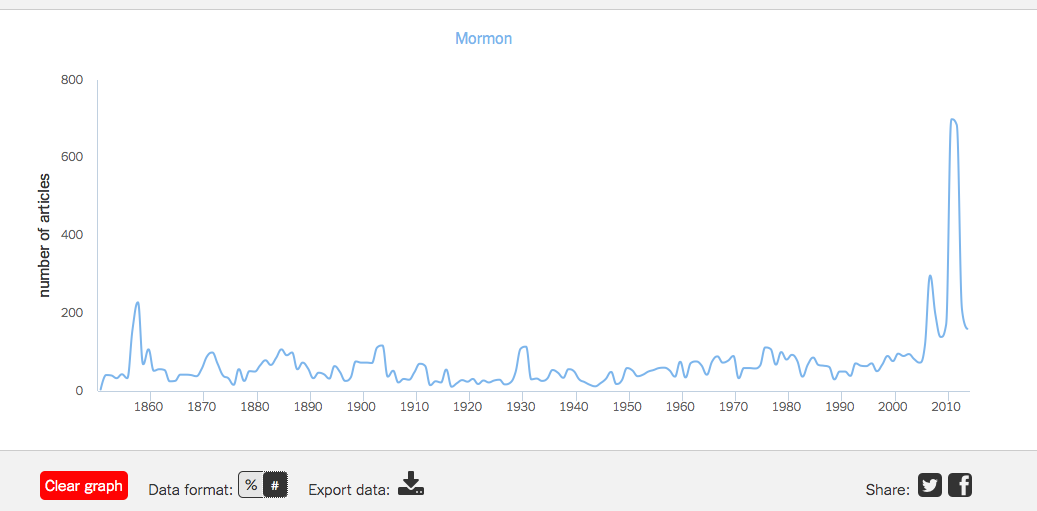
While, in 1858 there was a higher percentage of articles with the term Mormon, 2011 saw more articles written with the term Mormon. I would theorize that the New York Times publishes more articles currently than it did in 1858. This is very interesting as you try to grapple with the numbers. in 1858, a smaller corpus of articles yet a larger percentage covering or including the term Mormon than 2011.
Voyant
Voyant is a Text-Mining tool that can both be accessed through the web or you can download a standalone program. Instead of searching through a designated corpus of material (like the previous three options), it allows the user to upload their own collections via URL or uploading files. After the program has processed your material, it brings you to a page with various windows providing you with data. For this assignment, I uploaded a copy of The Picture of Dorian Gray by Oscar Wilde, both the magazine version and the subsequent novel. This Text-mining project then is comparing the two versions of the story.
In the center of the page, the text of the documents are provided. Here you can scroll through the body of text and it is interactive. Each word can be selected to find out its frequency throughout the documents. On the left side bar are colored dashes that highlight where that word is in the document. With these two documents, you can essentially run a frequency count/index any word that you click on. It is very interesting and fun to play with.
To the left of the main body of text is your summary information. You are provided with a word cloud, a summary of each document, and a frequency count for every word in the corpus. In all three windows, you can include a list of stop words (either a list you create or they provide multiple lists.) A stop word is a word that is inconsequential in the text. Examples would be (the, and, is, are, was…) By excluding stop words you can better sift through the data provided. To exclude words, you click the small gear/cog along the upper left corner of the window.
Along the right side column are windows providing specific information on words that you select from the text. You are given a line graph of the frequencies, the selected/keyword in context, and the selected words frequencies in each of the documents in the corpus. Here, Voyant, allows the user to investigate further their search/keyword. I chose the word “Dorian” out of the Novel text. The graph breaks the novel up into 10 segments and plots each segments total frequency of that word. I am also able to look at the context of each occurrence of “Dorian” as well as the frequency and trend.
Comparatively, Voyant provides the user with a much richer analysis of the corpus of documents. It can easily be manipulated to investigate various words, look for distinct words and even see the context of the words. The three previous programs do not offer those options. Finally, Voyant’s capabilities with my own sources over a designated corpus makes it that much more useful to me with my own research. In total, these tools provide an exciting glimpse into the possibilities of distant reading and digital history. I am both excited and intrigued by the possibilities these tools afford me.